Stats I/O: Not as Precise as You Think
The output from SET STATISTICS IO ON can be really helpful. Here’s the opening blurb from the docs page:
Causes SQL Server to display information about the amount of disk activity generated by Transact-SQL statements.
I’ve often seen it used during query tuning - for example, to gauge the difference in I/O activity before and after adding indexes.
However, I’ve come across several situations where some I/O is not reported, or isn’t reported in as much detail as one might expect, or is just generally confusing. Thus, this post, to show why you might want to take the numbers with a grain of salt.
Example 1: Parallel Scans
The first one comes from a post on Database Administrators Stack Exchange: STATISTICS IO for parallel index scan
To summarize the situation, the OP had a query that was scanning a clustered index. They were seeing significantly higher numbers reported in the logical reads portion of the STATISTICS IO output when the query ran in parallel vs. serially (with a MAXDOP 1 query hint). There is a demo of this behavior in the post, so I won’t reproduce it here.
Paul White (b | t) swooped in (two and a half years later 😜) with this really interesting explanation:
With an allocation-ordered scan, SQL Server uses allocation structures to drive the distribution of pages among threads. IAM page accesses are not counted in STATISTICS IO.
For a non-allocation-ordered scan, SQL Server breaks up the scan into subranges using index keys. Each internal operation to find and distribute a new page, or range of pages (based on a key range), to a worker thread requires accessing the upper levels of the b-tree. These accesses are counted by STATISTICS IO, as are the upper-level accesses made by worker threads when locating the start point of their current range. All these extra upper-level reads account for the difference you see.
In this case, the implementation details of how parallel scans work, which are not necessarily common knowledge across folks working with SQL Server, result in higher-than-expected numbers.
One could make the case that the allocation-ordered scan scenario under-reports I/O, although I’m not sure which bucket those reads would go into (since they are not data pages).
Example 2: Version Store Reads
This one also has its roots in a DBA Stack Exchange post: Long Running Query on Read-Only Replica that takes moments on the Primary
To (again) summarize the issue, the OP had an availability group with a readable secondary replica, and a specific query was running much more quickly on the primary than on the secondary. Significantly, for the purposes of this blog post anyway, STATISTICS IO didn’t show any difference when running the two queries.
Sean Gallardy (blog) quickly identified the issue as high version store reads. You can read the full Q&A there, but here’s an excerpt:
The version store itself is measured in generations and when a query is run which requires the use of the version store, the versioning record pointer is used to point to the TempDB chain of that row. […]
If the version store have many generations for these rows […] this will cause longer than average times for queries to run and generally in the form of higher CPU while all other items seemingly stay exactly the same […]
In this case, the output of STATISTICS IO tends to leave out quite a bit of the disk activity involved in the query, although it does show up in CPU usage and duration.
Being a real helpful guy, Forrest McDaniel (b | t) wrote up a Q&A (Does STATISTICS IO output include Version Store reads?) to confirm and document this somewhat-confusing behavior. As it turns out, you can catch these reads with Extended Events, although it’s probably not practical for a real-world investigation (the higher-than-expected CPU should be the giveaway).
Example 3: Physical Reads with Read-Ahead Disabled
This last one comes from a post on Eugene Meidinger’s (b | t) blog: T-SQL Tuesday #114 – An Unsolved SQL Puzzle
Eugene shows an interesting case where, despite fully clearing the buffer cache, a query against a heap table reports 3,808 logical reads, but only 5 physical reads. Intuitively, all of the reads would be physical. He went so far as to disable read-ahead using trace flag 652.
I profiled the heap scan with read-ahead enabled vs. disabled using PerfView:
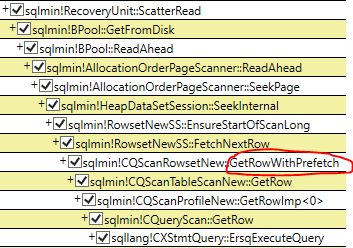
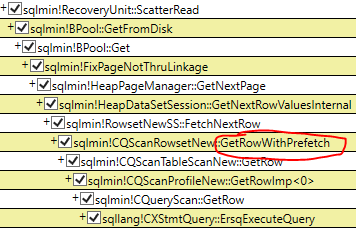
Both queries appear to go through a code path that calls “GetRowWithPrefetch,” but they branch differently from there (the read-ahead version calls AllocationOrderPageScanner::ReadAhead, while the read-ahead-disabled version does not - at least, my profile didn’t pick it up if it did). I don’t know much else about what’s going on there 😁
Based on that, though, we can see that SQL Server is still doing some kind of prefetching to reduce physical I/O, despite read-ahead being disabled. The file_read_completed extended event shows that those 5-ish reads don’t cover it. Here’s the stats I/O output from a sample run I did:
Table 'Person'. Scan count 1, logical reads 3808, physical reads 1,
read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
The XE picked up 490 “read completed” events for that database. Each of them was 65,536 bytes (exactly 64 KB - or one extent) in size, which totals up to 31,360 KB. Dividing that by 8 tells us that 3,920 8 KB pages were read from that data file - which is in the ballpark of the amount of logical reads reported by STATISTICS IO.
For what it’s worth, the extremely low physical reads appear to be a bug that only manifests the first time this query is run after the table is created. Clearing the buffer pool again, I get this output:
Table 'Person'. Scan count 1, logical reads 3808, physical reads 478,
read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
And the XE reported 480 “read completed” events:
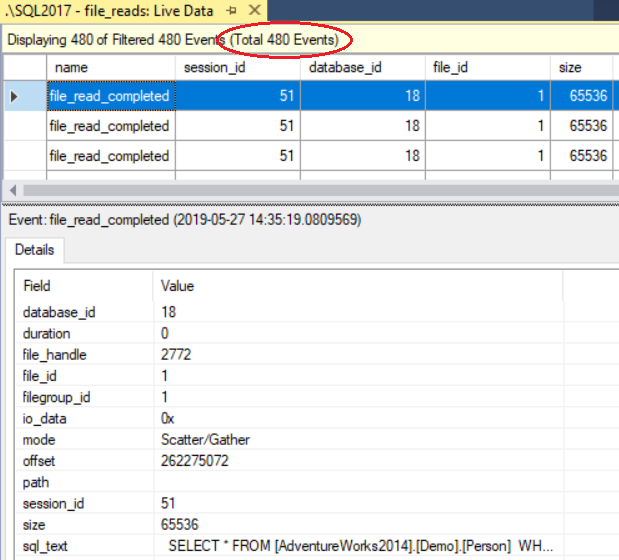
In this case, it seems that physical reads are actually reporting the number of reads performed by the storage engine, rather than the number of pages read from disk, which contradicts the documentation (linked earlier):
physical reads - Number of pages read from disk.
As a side note, pages are being read in extent-sized chunks because of some behavior I had never heard of called “buffer pool ramp up” which is described on the Microsoft PFE blog:
You’ll also notice that the smallest IO is 64K in size. In this case we are reading extents because my buffer pool hadn’t ramped up quite yet. During the Ramp up phase which is before the buffer pool committed memory reaches the target memory, in order to expedite the ram up process every single page read is aligned into 8 page read requests. If my buffer pool had been ramped up, then a single page ready would be an 8K IO.
If you want to see physical reads line up with logical reads, it seems you’ll need to set max memory to a low number and fill the buffer pool beforehand, etc.
Summary
There are some surprising things about the output of STATISTICS IO:
- For parallel scans, logical reads can report numbers higher than the number of actual pages read into the buffer pool, due to the way that pages are distributed among worker threads
- When snapshot, RCSI, or AG readable secondaries are involved, version store reads are not reported at all
- Physical reads may report the number of physical I/O’s performed, rather than the number of 8 KB pages read from disk
It’s likely there are lots of other nuances and edge cases, but these are the ones I came across recently.
Of course, this is still a great tool. But it should be taken with a grain of salt, and probably shouldn’t be used when very precise measurements are needed.