A Parallel Nested Loops Join Optimization
How a Parallel Loop Join Usually Works
This query uses the 2010 version of the Stack Overflow database running on SQL Server 2017:
SELECT *
FROM dbo.PostTypes pt
INNER LOOP JOIN dbo.Posts p
ON p.PostTypeId = pt.Id
WHERE pt.[Type] IN ('TagWiki', 'TagWikiExerpt')
OPTION
(
USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'),
MAXDOP 2
);
We want to get all of the “TagWiki” and “TagWikiExerpt” posts, which is 1,014 rows out of the total 3,744,192 rows in the whole dbo.Posts table.
I’m using a LOOP JOIN hint because the dbo.Posts table is large, and the optimizer wants to do a hash join. I’ve also added the ENABLE_PARALLEL_PLAN_PREFERENCE query hint because the optimizer wants to choose a serial plan for this query due to the cost estimates (1,183.78 for the serial loop join plan, 1,475.41 for the parallel version). Finally, I added a MAXDOP 2 hint just to make things work consistently if anyone is following along at home.
Here’s what the execution plan looks like in Plan Explorer:
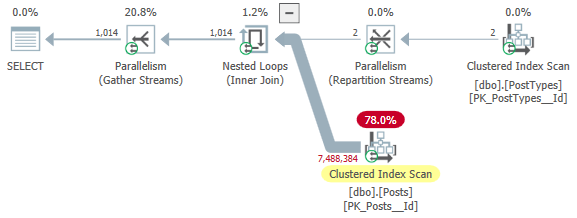
You can see that 7,488,384 rows came out of the Clustered Index Scan of dbo.Posts, which is exactly twice the number of rows in the table. If we go to the “Plan Tree” view, we can see that threads 1 and 2 each scanned the entire clustered index:
![[screenshot of plan tree showing rows per thread][2]](https://joshthecoder.com/assets/2019-05-19-rows-per-thread.PNG)
This essentially means that there are two serial scans of the posts table on the inner side of the join - one for each thread that got a row on the outer side.
This might be a little counter-intuitive for those used to seeing a “normal” (coorperative) parallel scan where all of the threads work together to read the whole index once.
Lazy Threading
This feels slightly worse when we only get one row on the outer input, like this:
SELECT *
FROM dbo.PostTypes pt
INNER LOOP JOIN dbo.Posts p
ON p.PostTypeId = pt.Id
WHERE pt.[Type] IN ('TagWiki')
OPTION
(
USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'),
MAXDOP 2
);
![[screenshot of plan tree showing rows all on thread 1][3]](https://joshthecoder.com/assets/2019-05-19-rows-per-thread-unbalanced.PNG)
The index is only scanned once, since there’s only one matching value. But thread 1 does nothing here, it just sits there. Maybe it’s at least cheering thread 2 on. Moral support, you know.
The Optimization
I first read about this as a footnote to an answer from Paul White on Database Administrators Stack Exchange. The question was “Actual rows read in a table scan is multiplied by the number of threads used for the scan,” which is about the “normal” situation described above. I’ve since read about this optimization again in the book “Microsoft SQL Server 2012 Internals” by Kalen Delaney (in the chapter on parallelism).
Paul’s footnote says:
There is one general exception to this, where one can see a true co-operative parallel scan (and exchanges) on the inner side of a nested loops join: The outer input must be guaranteed to produce at most one row, and the loop join cannot have any correlated parameters (outer references). Under these conditions, the execution engine will allow parallelism on the inner side because it will always produce correct results.
We know, from trying it, that there is only one row in dbo.PostTypes that has [Type] = 'TagWiki' - but how can we guarantee that (as far as the optimizer is concerned)?
One way would be to add a unique constraint to that column:
ALTER TABLE dbo.PostTypes ADD CONSTRAINT UQ_Type UNIQUE (Type);
Running the second query again, we get this plan - which has the same general shape except that the scan of dbo.PostTypes is now a seek:
![[screenshot of execution plan showing the seek on PostTypes][5]](https://joshthecoder.com/assets/2019-05-19-seek-plan.PNG)
As before, 3,744,192 rows come out of the scan of dbo.Posts (all the rows). But looking at the plan tree view shows us the magic:
![[screenshot of plan tree showing the cooperative scan][6]](https://joshthecoder.com/assets/2019-05-19-rows-per-thread-cooperative.PNG)
Both threads 1 and 2 worked together to scan the index only once, which improves the overall duration of the query - yay!
You’ll notice the work was distributed a little unevenly - this is normal, and is subject to how busy the CPU cores are that are running this query. In this case, thread 1 was finishing its work faster, so it got more rows. Thread 2 was on a core that was busy doing other stuff - probably running my godforsaken virus scanner. Or (the slightly less godforsaken) Windows Updates.
Tell Me Everything
This little trick is a great reminder that it’s helpful to give SQL Server as much information as possible, so that it came make the best decisions available in terms of query execution. Good statistics, foreign key relationships, unique constraints, appropriate data type sizes - all of these details can help to produce better plans and faster queries.
Thanks for reading!