SSDT problems: Table Rebuilds
Series on SSDT Problems
Tables rebuilds can wreak havoc on your database. So what are they, why are they bad, and what can you do about them?
What is an SSDT table rebuild?
I’m glad you asked. When deploying an SSDT project, SSDT compares the source code (your project) with the destination (the target database) to determine how they are different, and what T-SQL commands are needed to bring the target in line with the source.
Certain types of column changes will cause SSDT to decide to do the following:
- Create a brand new table (with a crazy-looking name) that matches the schema defined in the source
- Copy all of the data from the real table into this new table
- Drop the original table
- Rename the new table to replace the original table
All of this is done inside a SERIALIZABLE transaction.
The rebuild code is always replaced with a comment warning you what’s about to happen. The whole code block looks a bit like this:
GO
PRINT N'Starting rebuilding table [dbo].[Post]...';
GO
BEGIN TRANSACTION;
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SET XACT_ABORT ON;
CREATE TABLE [dbo].[tmp_ms_xx_Post] (
[Id] INT IDENTITY (1, 1) NOT NULL,
[CommentCount] INT NULL,
[PostType] VARCHAR (10) NOT NULL
);
IF EXISTS (SELECT TOP 1 1
FROM [dbo].[Post])
BEGIN
SET IDENTITY_INSERT [dbo].[tmp_ms_xx_Post] ON;
INSERT INTO [dbo].[tmp_ms_xx_Post] ([Id], [PostType])
SELECT [Id],
[PostType]
FROM [dbo].[Post];
SET IDENTITY_INSERT [dbo].[tmp_ms_xx_Post] OFF;
END
DROP TABLE [dbo].[Post];
EXECUTE sp_rename N'[dbo].[tmp_ms_xx_Post]', N'Post';
COMMIT TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
So why is this bad?
I’m sure you are appalled by the code above to the point where little explanation is needed, but here are a few of the highlights:
- it uses the SERIALIZABLE isolation level (the least concurrency-friendly one) - this is highly likely to cause blocking if there is any other activity going on in the system
- It inserts every single row from the original table into the new table. For small tables, this is fine. But for tables with many rows, or with very large data types, this can result in a MASSIVE amount of transaction log file growth
- It drops the original table - more transaction log growth, and blocking
What can we do about it?
Column Ordinality
Consider the following table:
CREATE TABLE [dbo].[Post]
(
[Id] INT IDENTITY(1,1) NOT NULL,
[PostType] VARCHAR(10) NOT NULL
)
As a very misguided developer, I feel like my shiny new CommentCount should go between the Id and PostType columns, because it looks nicer:
CREATE TABLE [dbo].[Post]
(
[Id] INT IDENTITY(1,1) NOT NULL,
[CommentCount] INT NULL,
[PostType] VARCHAR(10) NOT NULL
)
By default, SSDT sees the difference in the ordinal position of the columns and wants to sync them back up. So it will rebuild the whole table to accomplish this. A new “Ignore Column Order” option was added last year to opt out of this behavior:
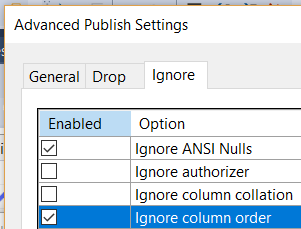
Dropping / renaming columns
Similar to the above, dropping a column can cause the table to rebuild the table to get the column order right. Use the same setting to avoid this.
I included renaming columns here as well, as SSDT often sees a rename as a drop and re-add. To avoid the drop and re-add behavior, you can rename columns inside the design pane in Visual Studio (which will update the refactorlog.xml file, used at deploy to choose the correct deployment behavior).
I tend to not use the design pane much for various reasons (I don’t like the formatting and capitalization choices it makes in the generated T-SQL, and adding named constraints requires a lot of clicking and bouncing back and forth from the design pane to the T-SQL editor). But renaming columns is a good time to use it.
Data types / NULL-ability
This one is a bit trickier. Sometimes, data types changes will cause the rebuild behavior to occur. Similarly, changing a column between NULL and NOT NULL can do the same.
The resolution to this one is to use “pre-DAC” scripts - basically, a T-SQL script you can run to manually make your rebuild-causing changes in a less production-impacting way. I’ve posted an answer about this on Database Administrators Stack Exchange:
SQL Server - Adding non-nullable column to existing table - SSDT Publishing
I plan to flesh that out in a blog post in this “SSDT Problems” series soon.