Troubleshooting an AG Failure
I’m going to go a little outside my comfort zone and talk about Windows Server Failover Clustering (WSFC) settings.
Specifically as those settings relate to availability groups, and how they can affect the reliability of the AG.
The Scenario
I’ve got a two-node synchronous availability group, with a File Share Witness as the third quorum vote. One evening, the File Share Witness was taken down for maintenance. I received an alert that both the primary and secondary replicas went into the “RESOLVING” state. Then, 15 seconds later, both servers returned to their previous statuses (so no failover occurred).
This resulted in 15 seconds of downtime for the application. We take downtime very seriously, so I started looking into the root cause.
Investigating: the SQL Server Error Log
My first stop was the SQL Server error log on the primary replica, where this message was prominently displayed:
Always On: The local replica of availability group ‘agMyDatabaseProd’ is preparing to transition to the resolving role in response to a request from the Windows Server Failover Clustering (WSFC) cluster. This is an informational message only. No user action is required.
The availability group database “MyDatabase” is changing roles from “PRIMARY” to “RESOLVING” because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required.
As I mentioned before, 15 seconds later everything goes back from RESOLVING to PRIMARY:
Always On: The local replica of availability group ‘agMyDatabaseProd’ is preparing to transition to the primary role in response to a request from the Windows Server Failover Clustering (WSFC) cluster. This is an informational message only. No user action is required.
The availability group database “MyDatabase” is changing roles from “RESOLVING” to “PRIMARY” because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required.
So…no failover, just a weird blip in the AG’s uptime.
Since the messaging here indicates that the state change occurred because of a request from WSFC, my next stop is the Cluster log. But first, a little bit of background about the WSFC Resource Hosting Subsystem.
WSFC Resource Hosting Subsystem (RHS)
There’s a great post on MSDN about Understanding how Failover Clustering Recovers from Unresponsive Resources.
It goes into a lot of detail about how the different resources defined in the WSFC cluster configuration respond to failure. This is the part that grabbed my attention in particular:
If there are multiple resources hosted on that node, they may be hosted in the same RHS process. That means when RHS terminates and restarts to recover an individual resource, all resources being hosted in that specific RHS process are also restarted.
At this point, I suspect that the AG resource was running in the same RHS process as the File Share Witness, and thus was along for the ride (restart) during RHS recovery.
The other important bit was here:
The cluster service will automatically set the resource common property SeparateMonitor to mark that resource to run in its own dedicated RHS process, so that in the event that the resource becomes unresponsive again; it will not affect others.
So fortunately, the file share came back up in it’s own rhs.exe process, so it wouldn’t cause that problem again.
Investigating: The WSFC CLuster Log
To get the cluster log, I logged in to the primary server, opened PowerShell, and ran:
Get-ClusterLog
Reviewing the log, I see this:
ERR [RHS] RhsCall::DeadlockMonitor: Call LOOKSALIVE timed out by 16 milliseconds for resource ‘File Share Witness’. WARN [RCM] rcm::RcmResource::HandleMonitorReply: Resource ‘File Share Witness’ has crashed or deadlocked; marking it to run in a separate monitor.
So the file share witness has misbehaved, and the resource is being restarted in a separate monitor process (as described earlier).
ERR [RHS] WER report is submitted. Result : WerReportQueued.
A minidump was created for the Windows Error Reporting, so I’ll be interested to check that out.
INFO rcm::RcmMonitor::RestartResources[RCM] rcm::RcmMonitor::RestartResources: Monitor restart for resource agMyDatabaseProd_12.3.4.567 INFO [RCM] rcm::RcmResource::ReattachToMonitorProcess: (agMyDatabaseProd_12.3.4.567, Online)
The availability group “resource” was running in the same Resource Hosting Subsystem (rhs.exe) process as the File Share Witness, so it is being restarted as well.
INFO [RCM] rcm::RcmMonitor::RestartResources: Monitor restart for resource File Share Witness INFO [RCM] rcm::RcmResource::ReattachToMonitorProcess: (File Share Witness, Online) INFO [RCM] Separate monitor flag has changed for resource ‘File Share Witness’. Now hosted by RHS process 0
This is the File Share Witness resource being restarted in a separate rhs.exe process.
Finally, 15 seconds later:
INFO [RHS] Resource agMyDatabaseProd_MyListenerName has come online. RHS is about to report status change to RCM
The AG resource comes back up.
Investigating: The Crash Dump
Another post I found helpful during this process was Behavior of the LooksAlive and IsAlive functions for the resources that are included in the Windows Server Clustering component of Windows Server 2003. However, there are a couple of problems with it:
- it’s for 2003, and I’m on 2012,
- there is not a corresponding post for 2012 resources,
- the resource we’re dealing with isn’t on that page
Despite that, I glanced through the crash dump file created for this failure, and found this:
8 Id: 614.1110 Suspend: 0 Teb: 00007ff7`edb10000 Unfrozen
# Child-SP RetAddr Call Site
00 000000d4`9ad9ecd8 00007ff8`0fd24232 ntdll!NtCreateFile+0xa
01 000000d4`9ad9ece0 00007fff`f8b8987d KERNELBASE!CreateDirectoryW+0xd2
02 000000d4`9ad9edd0 00007fff`f8b88272 clusres2!WrValidateShare+0x105
03 000000d4`9ad9f280 00007ff7`edda40e6 clusres2!WrpIsAlive+0xda
04 000000d4`9ad9f2f0 00007ff7`edda440d rhs!IsAliveCall::CallIntoResource+0x1d6
05 000000d4`9ad9f3f0 00007ff7`edd9f3c2 rhs!LooksAliveCall::CallIntoResource+0x20d
06 000000d4`9ad9f4d0 00007ff7`edd9f1fe rhs!RhsCall::Perform_NativeEH+0x18e
07 000000d4`9ad9f580 00007ff7`eddbe167 rhs!RhsCall::Perform+0x4e
08 000000d4`9ad9f5b0 00007ff7`eddbda73 rhs!cxl::Delegate<void __cdecl(bool)>::operator()+0x63
09 000000d4`9ad9f620 00007ff8`1293b267 rhs!cxl::ThreadPool::StaticWorkItemRoutine+0x83
0a 000000d4`9ad9f720 00007ff8`12958e75 ntdll!RtlpTpWorkCallback+0x127
0b 000000d4`9ad9f800 00007ff8`100613d2 ntdll!TppWorkerThread+0x465
0c 000000d4`9ad9fbe0 00007ff8`129354f4 kernel32!BaseThreadInitThunk+0x22
0d 000000d4`9ad9fc10 00000000`00000000 ntdll!RtlUserThreadStart+0x34
So it appears that the “IsAlive” entry point for this resource lives in an assembly called “ClusRes2.dll.” And the way it’s implemented is that it calls into Windows APIs to attempt to create a directory and file on the file share. Further confirmed later in the cluster log:
ERR [RES] File Share Witness
: Failed to create or open directory \\ServerName\ShareName\6202f55b-61b8-4b4b-811f-3302f0847ad9, error 121. ERR [RES] File Share Witness : Failed to arbitrate for \\ServerName\ShareName\6202f55b-61b8-4b4b-811f-3302f0847ad9 with 121. ERR [RCM] Arbitrating resource 'File Share Witness' returned error 121
This failed (which in my case was because the file share server was down for maintenance), which is what caused the whole problem to begin with.
How to Fix This
When setting up the WSFC resources for your AG, make sure to run the File Share Witness in a separate monitor from the beginning. This should be part of ANYONE’s AG setup checklist. All you have to do is check this box:
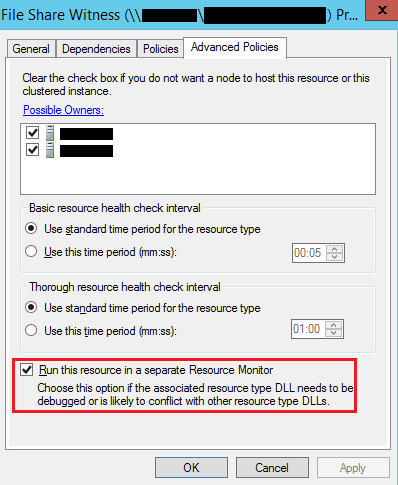
This way you can prevent unnecessary downtime if your file share is temporarily down.
In my case, there wasn’t too much of an impact. However, if you have high transaction throughput, or applications that that don’t respond well to reconnecting to the database, this 15 second delay in processing could be a significant issue!
I think there is really a lack of information about this setting, and really the whole topic, online - so I hope this helps someone!